
DALL·E 2 Presentation
Contents
DALL·E 2 Presentation#
Note
Author: Jason Schuehlein (js450)
Email: js450@hdm-stuttgart.de
Contents
Introduction Text-To-Image#
Text-To-Image (TTI) ist ein Subtask der Bildsynthese und beschreibt Conditional Image Generation, also die Generierung von Bildsamples unter der Bedingung eines Labels \(p(x|y)\). Zero-Shot TTI geht einen Schritt weiter und ermöglicht auch Generierung von Daten ausserhalb des gelernten Trainingsdatensatzes.
Generative Adversarial Nets (GAN) sind häufig Vertreter im Bereich TTI. Seit einiger Zeit werden aber auch verstärkt Diffusion Models verwendet, dazu später mehr.
Die Qualität von TTI Modellen wird gemessen an:
Fidelity: Übereinstimmung mit den Originalbildern
Diversity: Abdeckung der gesamten Variation der Originalverteilung
Kombiniert kann man das an der sog. Fréchet inception distance (FID) ablesen.
Fréchet inception distance (FID)
Die Fréchet inception distance (FID) ist eine Metrik zur Beurteilung der Qualität von Bildern generiert durch generative Modelle. Im Vergleich zum Inception Score (IS), wird nicht nur die Verteilung der generierten Bilder betrachtet sondern die Verteilungen der echten sowie generierten Bilder verglichen. FID kombiniert Fidelity und Diversity in einer Zahl.
Die FID entspricht der quadrierten Wasserstein Distanz zwischen zwei multivariaten Gaussverteilungen.
Recent Work#
DALL·E#
Der namentliche Vorgänger zu DALL·E 2 wurde am 5. Januar 2021 in einem OpenAI Blog Eintrag vorgestellt und mehrere Wochen später, am 24. Februar 2021, wurde das Paper eingereicht mit dem Titel “Zero-Shot Text-to-Image Generation” [RPG+21].
DALL·E besteht aus zwei Modulen: dem Discrete Variational Autoencoder (dVAE) und einem Decoder-Only Sparse Transformer. Letzterer basiert nach eigenen Angaben auf einer Variante von GPT-3.
Lediglich der Code des dVAE Moduls wurde von OpenAI auf GitHub veröffentlicht unter openai/DALL-E. Eine inoffizielle aber komplette Implementierung findet sich hier lucidrains/DALLE-pytorch.
Öffentlich zugänglich war das Model nie, alternativ kann man aber CrAIyon bzw. borisdayma/dalle-mini verwenden, ein Versuch von Dayma et al. [DPC+21], DALL·E zu reproduzieren.
Folgende Eigenschaften von DALL·E sind herauszustellen:
Variable Binding: Korrektes Zuweisen von Attributen zu Objekten (Fig. 1)
Mehrere Objekte in einem Bild (Fig. 1)
Beachtung von Perspektive (Fig. 2)
Interne und Externe Objektstrukturen (Fig. 3)
Zeitliches und geographisches Wissen

Fig. 1 DALL·E - Multiple Objects and Variable Binding Examples.
https://openai.com/blog/dall-e/.#
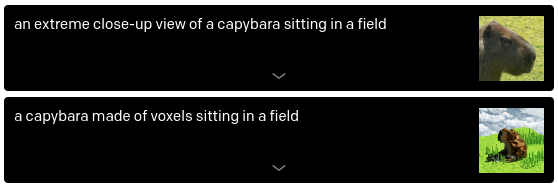
Fig. 2 DALL·E - Perspective Examples.
https://openai.com/blog/dall-e/.#
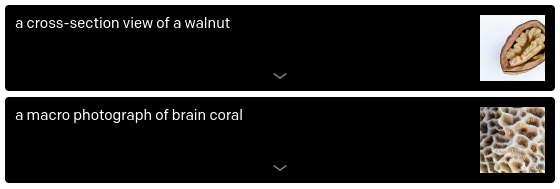
Fig. 3 DALL·E - Perspective Examples.
https://openai.com/blog/dall-e/.#
CLIP#
OpenAI’s Contrastive Language Image Pretraining (CLIP) von wurde am 26. Februar 2021 vorgestellt in “Learning Transferable Visual Models From Natural Language Supervision” von Radford et al. [RKH+21].
CLIP besteht aus zwei Encodern, einem der Text in Text Embeddings umwandelt und ein weiterer der Bilder in Image Embeddings umwandelt.

Für einen Batch aus \(N\) Image-Text Paaren \((x,y)\) werden alle Text Embeddings allen Image Embeddings gegenübergestellt. CLIP wird nun darauf trainiert die \(N\) der \(N \times N\) möglichen Image-Text Paare zu identifizieren die korrekt sind. Verwendet wird hierbei die Cosine Similarity, diese soll für die korrekten Paare maximiert und die inkorrekten Paare minimiert werden.
CLIP lernt einen “joint representation space” für Texte und Bilder.
Refresher: Cosine Similarity
Das Skalarprodukt
wird umgeformt um die Cosine Similarity \(S_C\) zu erhalten
GLIDE#

GLIDE ist ein weiteres TTI Model von OpenAI und wurde am 20. Dezember 2021 in dem gleichnamigen Paper “GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models” von Nichol et al. [NDR+22] vorgestellt.
Zwar bekam GLIDE keinen eigenen Blog Eintrag auf der OpenAI Website, dafür wurde aber der Code offiziell auf GitHub veröffentlicht unter openai/glide-text2im. Neben Checkpoints für eine kleinere Version, genannt “GLIDE (filtered)”, gibt es dort auch Notebooks zur Inferenz von Text-To-Image und Inpainting.
Trainiert wurde diese kleine Version mit stark gefilterten Trainingsdaten, um Gewalt und Hass Symbole zu entfernen. Sogar Humanoiden wurden komplett entfernt. Durch die relativ kleine Grösse scheitert GLIDE (filtered) jedoch häufig an Variable Binding (siehe Fig. 6)

Fig. 6 First row shows the original GLIDE, followed by a smaller version trained on the same dataset as the full-sized one. In the third row, we see the smaller version trained on the filtered dataset instead. Finally, in the fourth row, the authors used CLIP to guide the model towards better results [NDR+22].#
DALL·E 2#

DALL·E 2 wurde von OpenAI entwickelt und mit dem Blog Post des Projekts am 06. April 2022 veroeffentlicht. Das dazugehörige Paper Hierarchical Text-Conditional Image Generation with CLIP Latents von Ramesh et al. [RDN+22] wurde eine Woche später am 13. April 2022 vorgelegt und beschreibt unCLIP, die grundlegende Architektur hinter DALL·E 2. Das Deployment dessen, die sog. DALL·E 2 Preview ist eine modifizierte “production version” [RDN+22].
Zur Veröffentlichung war DALL·E 2 State of the Art im Bereich Text-To-Image. Im Vergleich zu seinem namentlichen Vorgänger hat DALL·E 2 eine höhere Auflösung und ein höheres Level an Photorealismus (siehe Fig. 8 vs. Fig. 10).

Fig. 8 DALL·E 1: “a painting of a fox sitting in a field at sunrise in the style of Claude Monet” https://openai.com/dall-e-2/.#


Fig. 10 DALL·E 2: “a painting of a fox sitting in a field at sunrise in the style of Claude Monet” https://openai.com/dall-e-2/.#
Style of Claude Monet

Fig. 11 The Wheat Field, Claude Monet (1881)#
Neben Text-to-Image besitzt DALL·E 2 aber auch noch weitere Fähigkeiten:
Editieren von Bildern durch Inpainting (siehe Fig. 12),
Varianten eines Input Bildes erzeugen (siehe Fig. 13) und
Text Diffs - Durch Text gesteuerte Manipulation im Latent Space (siehe Fig. 14).

Fig. 12 DALL·E 2 giving Mona Lisa a mohawk via Inpainting.
https://openai.com/dall-e-2/.#

Fig. 13 DALL·E 2 Variations on “a painting of a fox sitting in a field at sunrise in the style of Claude Monet”. Created by myself with DALL·E 2: https://labs.openai.com/s/fb5LwnfumVDJ5NbNFiql16XJ#

Fig. 14 DALL·E 2 Text Diff [Ram]: \((\text{image of victorian house}) + \text{"a modern house"} − \text{"a victorian house"}\)#
Initial bekamen 400 ausgewählte Personen Zugriff auf eine API über die Inferenzen durchgeführt werden können und über eine Waitlist werden weitere Nutzer zugelassen. Stand 18. Mai 2022 wurden bereits 3 Millionen Bilder generiert und es sollen \(\approx 1000\) neue Nutzer pro Woche freigeschaltet werden [DAL22].
Offizieller Grund für den beschränkten Zugang sind Sicherheitsbedenken seitens OpenAI [MAB+22].
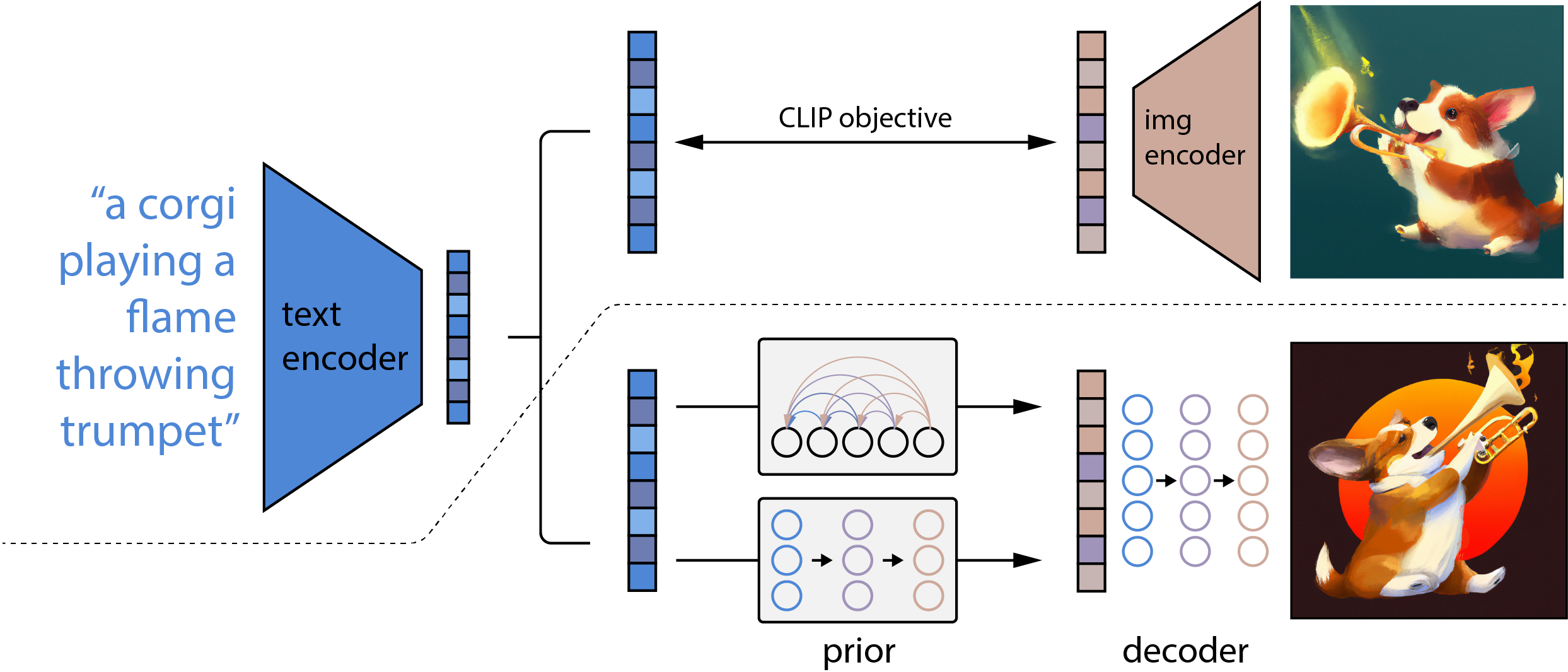
In Fig. 15 ist die grundlegende Architektur dargestellt, sie besteht aus 4 Elementen:
CLIP Model um Text Embeddings zu generieren
Prior um Text Embeddings in Image Embeddings umzuwandeln
Decoder um aus Image Embeddings ein Bild zu generieren
2 Upscaler \(64^2 \rightarrow 256^2\) und \(256^2 \rightarrow 1024^2\)
Tatsächlich ist DALL·E 2 eher eine Weiterentwicklung von GLIDE (Fig. 9). Die eigentliche Neuerung besteht darin, dass ein Diffusion Model statt auf Text Encodings, nun auf CLIP Image Embeddings trainiert wird und diese rückgängig macht, daher auch der Name “unCLIP”. Aus diesem “Umweg” resultieren vorteilhafte Eigenschaften, so kann man beispielsweise den CLIP Latent Space erkunden und visualisieren.
Ähnlich wie bei DALL·E, wurde kein Code des Models veröffentlicht, deshalb wurde von der Open-Source Community ein Versuch gestartet, DALL·E 2 (bzw. das im Paper spezifizierte unCLIP) zu reproduzieren, es gibt also eine inoffizielle Implementierung in dem GitHub Repository lucidrains/DALLE2-pytorch.
Diese ist grösstenteils abgeschlossen, und Stand 25. Juni 2022 trainiert die Community des AI Vereins LAION einen ersten Prior und auch erste Decoder sind in der Community zu finden.
Ein erstes Inferenz Notebook der Community welches findet sich unter LAION-AI/dalle2-laion.

Fig. 16 Inference on the same fox prompt as above, using LAION-AI/dalle2-laion. Inference Time: ~10min (Tesla T4).#
ThisImageDoesNotExist ist eine kleine Demo bei der man raten muss welche Bilder von einem Menschen sind und welche von DALL·E 2 generiert wurden. Der Durchschnitt liegt bei \(18/30\) korrekt zugeordneten Bildern.
API Access#
Unter den 400 Auserwählten waren zu Beginn nur 200 OpenAI Mitarbeiter, 10 Künstler, “ein paar Dutzend” anerkannte Wissenschaftler und 165 “company friends”. Über eine Waitlist wurden über Zeit auch weiteren Personen eingeladen, bis zu 1.000 Personen pro Woche [DAL22].
Die Verwendung der API ist nur für persönliche, nicht-kommerzielle oder wissenschaftliche Zwecke zulässig. User müssen beim Posten von generierten Bildern eindeutig kennzeichnen ob und welcher Teil des Bildes von DALL·E 2 generiert wurde. Ausserdem enthält jedes generierte Bild ein kleines Wasserzeichen in der unteren rechten Bildecke (siehe Fig. 17).

Fig. 17 The DALL·E 2 signature present in every image it creates via the API [MAB+22].#
Ausserdem filtert die API Input nach Kriterien wie z.B. Sicherheitsbedenken (sexualisierte oder suggestive Bilder von Kindern, Gewalt, politischer Content und “toxischer Content”).
Allerdings geschieht diese Filtering von Input Text und Input Bild unabhängig voneinander. Demnach könnte man das Model anweisen Inpainting für ein Bild einer Dusche mit dem Text “a woman” zu machen, und dabei potenziell ein Bild einer nackten Frau generieren.
Diffusion Basics#
Diffusion Modelle sind, wie auch GANs, Generative Modelle, sie generieren Daten ähnlich zu den Trainingsdaten mit denen sie trainiert wurden. Beschrieben wurden sie u.a. von Ho et al. [HJA20] mit Inspiration aus den “nonequilibrium thermodynamics”.
A diffusion model is trained to undo the steps of a fixed corruption process.
—Ramesh [Ram]
Jeder Zeitschritt addiert eine kleine Menge Gaussian Noise und verringert somit die Information im Bild. Nach dem letzten Schritt ist das Bild von purer Gaussian Noise nicht mehr unterscheidbar. Das ist der sog. Forward Diffusion Process.
Da ein State bzw. ein Bild immer nur von dem vorherigen abhängig ist, kann der Prozess als Markov Chain modelliert werden (siehe Fig. 18).
Im Reverse Diffusion Process wird das Model wird nun darauf trainiert, den Prozess Schritt für Schritt rückgängig zu machen. Dabei lernt es Informationen wiederherzustellen, die jedem Schritt existiert haben könnten.

Fig. 18 Forward \(q(x_t|x_{t-1})\) and Backwards \(p_{\theta}(x_{t-1}|x_t)\) Diffusion Process as a Markov Chain. [HJA20]#
Gibt man nun Rauschen auf das gelernte Model und wendet es mehrfach darauf an (\(\approx 1000\) Schritte sind üblich), dann wird das Bild immer realistischer bis es komplett rauschfrei ist und aus der Verteilung der Trainingsdaten stammt.
Ein grosser Vorteil der Diffusion Modelle gegenüber GANs ist, dass kein Adversarial Training erforderlich ist. Ausserdem ist die Implementierung sehr flexibel, die einzige Anforderung an die darunterliegende Architektur ist, dass Input und Output gleich gross sein müssen. In der Praxis werden häufig UNets verwendet.
Nachteil der Diffusion Modelle gegenüber GANs sind jedoch die längeren Inferenzzeiten.

Fig. 19 DDPM applied on CelebA-HQ, showing the Reverse Process starting at different timesteps [HJA20]#
Guided Diffusion
CLIP Guidance wird zur Inferenzzeit angewandt, es wird bei jedem Schritt von CLIP berechnet, wie hoch die Similarity zwischen Text Embedding und dem denoisten Bild ist. Der Gradient des CLIP Scores wird nun verwendet um das denoiste Bild in die Richtung zu verändern in der CLIP einen hohen Text-Image Match vorhersagt.
Classifier-free Guidance wird ebenfalls zur Inferenzzeit angewendet, jedoch benötigt man hierzu kein zusätzliches Model. Stattdessen wird zu einem Diffusion Step je ein Bild mit und ein Bild ohne Conditional generiert. Dann wird die Differenz beider Bilder berechnet und das denoiste Bild einfach weiter in diese Richtung bewegt, häufig multipliziert mit einer Guidance Scale.
Architecture#
Wie bereits beschrieben besteht DALL·E 2 aus folgenden Komponenten:
Der Prior \(P(z_i|y)\) erzeugt CLIP Image Embeddings \(z_i\) unter gegebener Caption \(y\)
Der Decoder \(P(x|z_i,y)\) erzeugt Bilder \(x\) unter gegebenen Image Embeddings \(z_i\) (und optional auch der Caption \(y\), bleibt aber hier ungenutzt)
Why \(P( x | y ) = P(x | z_i, y)P(z_i|y)\)?
Beide zusammen ergeben ein Generative Model \(P(x|y)\) für die Bilder \(x\) mit gegebenen Captions \(y\). \(P(x|y)\) kann geschrieben werden als
weil \(z_i\) eine deterministische Funktion von \(x\) ist. Weiter kann man mit der Kettenregel umformen und erhält
Man kann also aus der echten Verteilung \(P(x|y)\) samplen, indem man erst \(z_i\) mit dem Prior sampled und dann \(x\) mit dem Decoder.
Prior#
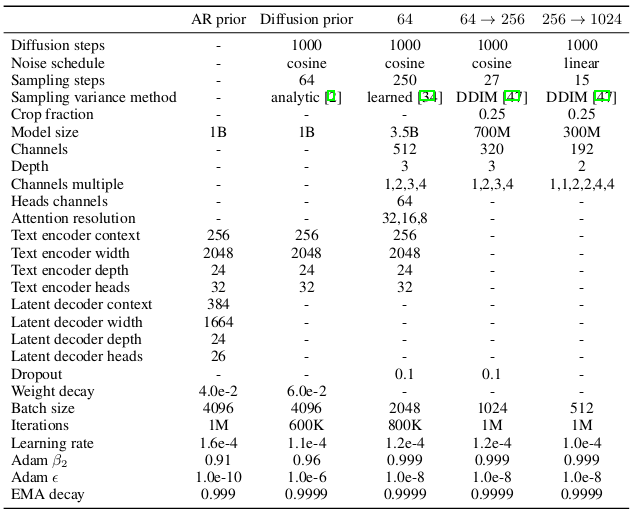
Der Prior generiert aus dem CLIP Text Embedding \(z_t\) eines Labels \(y\) ein CLIP Image Embedding \(z_i\). Hierfür haben die Autoren zwei verschiedene Model Klassen getestet: einen Autoregressive (AR) Prior und einen Diffusion Prior. Letzterer wurde als effizienter und qualitativ hochwertiger befunden und im Folgenden genauer betrachtet.
Diffusion Prior#
Wie bereits oben erwähnt ist eine Anforderung an Diffusion Modellen, dass Input und Output die gleiche Grösse haben, bei DALL·E 2 wird hier ein Decoder-Only Transformer mit Casual Attention Mask verwendet.
Um die Qualität zu verbessern, werden bei jedem Sampling je 2 \(z_i\) Samples generiert und das Sample ausgewählt das ein höheres \(z_i \cdot z_t\) aufweist. Ein höheres Skalarprodukt der beiden Embeddings bedeutet dass die Caption das Bild besser beschreibt (vgl. Training von CLIP).
Transformer Sequence
Die Sequenz auf welcher der Transformer agiert besteht aus:
Tokenization des Text
CLIP Text Embedding \(z_t\) der Tokens
Embedding des sktuellen Diffusion Timesteps
Noised CLIP Image Embedding zum aktuellen Timestep
“Final Embedding” welches verwendet wird um das Denoised CLIP Image Embedding \(z_i\) vorherzusagen
Loss Function
Der verwendete Loss ist eine Vereinfachung von der von Ho et al. [HJA20] verwendeten Loss Function bei DDPM, es wird lediglich der Mean Squared Error zwischen echtem \(z_i\) und der Vorhersage berechnet:
Decoder#
Der Decoder der in DALL·E 2 Verwendung findet ist eine leichte Modifikation des Diffusions Models GLIDE von Nichol et al. [NDR+22]. Zur Erinnerung: GLIDE generiert Bilder direkt aus Text Embeddings, ohne Umweg über CLIP Embeddings. Um diese Embeddings nun bei gleichbleibender Architektur in den Decoder einzubringen, werden die sie in das existierende Timestep Embedding projiziert. Ausserdem werden sie auch noch in 4 extra Token projiziert die an die Text Tokens des GLIDE Text Encoders angehängt werden.
Die Autoren entschieden sich für das Beibehalten des “text-conditioning pathway” des GLIDE Decoders unter der Annahme, dass das Diffusion Model dadurch Aspekte von Natural Language lernen könnte, die CLIP nicht erfasst, wie beispielsweise Variable Binding. Letztendlich wird er in DALL·E 2 aber nicht verwendet, weil er zu keinen merklichen Verbesserungen führte.
Durch sog. Classifier-free Guidance wurde die Sampling Qualität weiter verbessert, vorgestellt wurde diese Technik von Ho and Salimans [HS21].
Upsampler#
Die Diffusion Upsampler (\(64^2 \rightarrow 256^2\) und \(256^2 \rightarrow 1024^2\)) folgen der Unconditional ADMNet Architektur aus “Diffusion Models Beat GANs on Image Synthesis” von Dhariwal and Nichol [DN21].
Trainiert wurden die ADMNets auf leicht korrumpierten Bildern um die Qualität des Upsamplings zu verbessern. In Experimenten hat sich ausserdem gezeigt, dass eine Konditionierung auf die Bild Captions keinen sichtbaren Verbesserungen mit sich bringt.
Training Dataset#
Ähnlich wie schon bei GLIDE wurden die Trainingsdaten auf denen das Model trainiert wurde, gefiltert, um “explicit content” gering zu halten. Diesmal jedoch weniger aggressiv: Bilder und Captions die “grafische sexuelle sowie gewalttätige Inhalte” haben wurden entfernt, ebenso wie “Hate Symbols”.
Der Trainingsdatensatz besteht aus 2 Teilen:
Die CLIP Encoder wurden auf beiden trainiert und dann eingefroren. Prior, Decoder und Upsampler hingegen nur auf letzterem.
Limitations#
Trotz des grossen Fortschritts in Fidelity und Diversity der Samples die DALL·E 2 generieren kann, hat es auch einige Limitationen. Ganz besonders ist es schlechter als GLIDE im Bereich Variable Binding (siehe Fig. 21). Die Hypothese der Autoren ist dass CLIP selbst keine expliziten Attributs Zuweisung modellieren kann. Aber auch detailreichere Szenen oder zusammenängenden Text (siehe Fig. 22) schafft unCLIP nicht korrekt darzustellen.


Fig. 22 unCLIP prompted with: “A sign that says deep learning.” [RDN+22].#
In Fig. 23 sieht man eine groessere Gegenueberstellung der bisherigen Text To Image Modelle.

Further Work#
Google Imagen#

Fig. 24 A cherrypicked collection of Imagen generations [SCS+22].#
Googles Imagen wurde am 13. Mai 2022 in dem Paper Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding [SCS+22] vorgestellt und hat DALL·E 2 als State of The Art Model abgeloest.
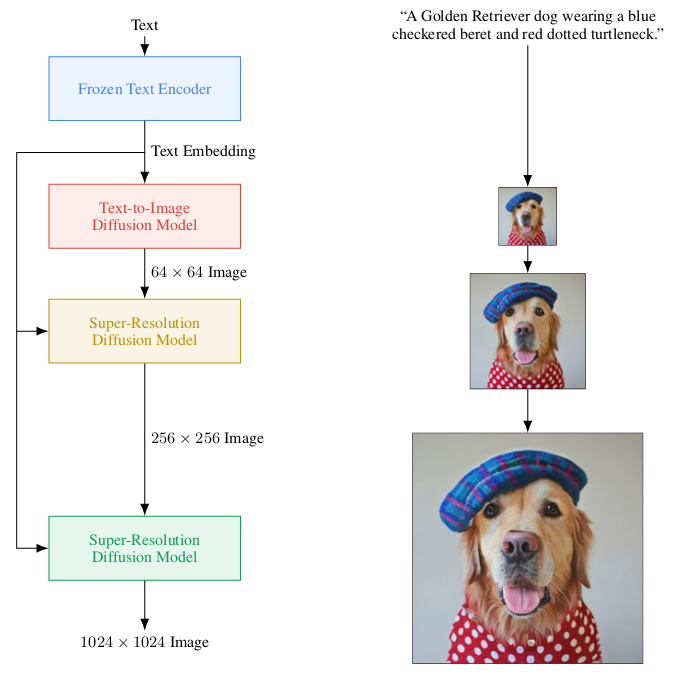
Imagen verzichtet hier also auf das “Layer of Indirection” über die CLIP Image Embeddings, verwendet wird stattdessen der mächtige Text Encoder T5-XXL, womit Imagen GLIDE ähnelt. Des weiteren wurden hier Text-Conditional Super-Resolution Modelle angewandt statt Unconditional wie in DALL·E 2.

Fig. 26 Imagen vs DALL·E 2 vs GLIDE: “A black apple and a green backpack.”.
Adapted from [SCS+22].#

Fig. 27 Imagen vs DALL·E 2 vs GLIDE: “A storefront with Text to Image written on it.”.
Adapted from [SCS+22].#
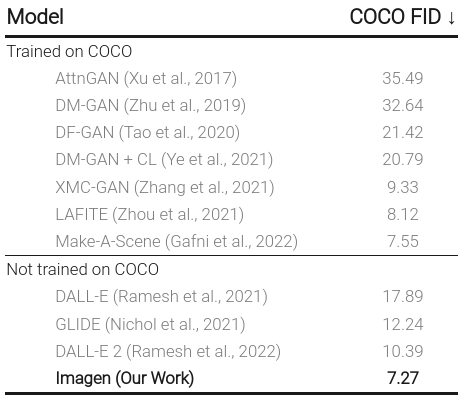
Fig. 28 Imagen is the new state-of-the-art on COCO FID. https://imagen.research.google#
Questions and Discussion#
Note
Was wuerdet ihr mit DALL·E 2 anfangen?